2016, the summary
This post is part of a chain of yearly summaries of noteworthy self-education and side-project work. I'm publishing these overviews to provide pointers to interesting resources, to show I'm serious about continuous self-improvement, and to inspire others to have fun with new technologies.
Previous year: 2015 <---> Next year: 2017
2016
The year started with a move to a larger apartment in Amsterdam. This meant much more space for side-projects, including home automation, a room for computer vision projects, and a new cat. Meanwhile, I clocked the fourth year of my startup, and while is was going good, it wasn't going unicorn-level great. This made me decide to explore some opportunities at the end of the year while working through linked-list sorting algorithms and interviews. But first, some projects.
Deep Learning
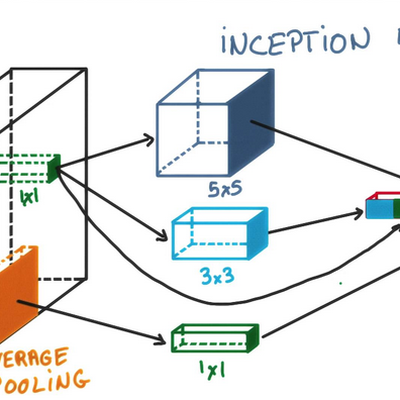
Despite studying artificial intelligence only a handful of years back, the field is moving quickly and everyone seems to be doing deep learning these days, the new brand for neural networks that are taking over the machine learning space. Although many problems can be solved with simpler machine learning approaches (or even without ML), Deep Learning is the new hype and every startup and corporate claims to be doing it. I invited some fellow former AI students over to kickstart a study group that would eventually do 5 months of biweekly meetings, deep-diving (pun intended) into the latest developments.
Together we went through Michael Nielsen's online book Neural Networks and Deep Learning, refreshing knowledge about neural nets, the back-propagation algorithm, and improvements like momentum, dropout, and CNNs and RNNs. The book contains examples in pure python (look ma, no libraries!) and drives back the need for understanding algorithmic details before starting to use deep learning libraries. Meanwhile, we started doing TensorFlow tutorials, and experimented with our own toy projects doing hard-writing detection (MNIST), object detection, and running existing github projects generating Obama speeches and Trump tweets.
Secondly, we read most of the Deep Learning book by Goodfellow, Bengio and Courville. This more theoretical book includes interesting sections on optimisation techniques, advanced recurrent architectures, deep learning library implementations, practical engineering methodology, and current research in deep reinforcement learning, representation learning, and more. This scientific book gave a great amount (too much?) details and will be awesome while doing research, but most of us found more satisfaction in our more informal discussions and the engineering-minded talks we watched. We closed the series of meetups making cocktails, by mixing together weird ingredients as suggested by IBM's Chef Watson, an app supposedly trained with deep learning on a molecular level.
I documented our journey in this github repository.
Data Visualisation & D3.js
I did a short udacity course to get a flavour of the possibilities of this cool visualisation library, and got a primer on interactive data visualisations in general to tell data-driven stories. The field of 'data science' and 'big data' would benefit hugely from practitioners with a good understanding of visual tools and skills in storytelling with data.
Tech impressions: D3.js is a medium-level visualisation tool build on top of the native DOM. It creates interactive visualisations consisting of SVG elements with nifty functional tools for animating DOM elements inside the SVG element directly. Its API includes data readers for various formats (incl. AJAX calls), smart mapping from data collections to function calls on newly created objects, and an enormous amount of predefined data-structures (trees, quadtrees, stacks, collections), algorithms, data wrangling (transformations, projections, scales, dates), and visualisation elements (basics, curves, polygons, histograms, pies, chords, voronoi; axes; colour spaces; forces; transitions and animations). It looks like a comprehensive set of micro-libraries with an intuitive declarative programming style and quick, visually appealing results.
Django & Project weblog
Django is a pretty flexible backend web framework that offers all the benefits of Python (the language, speedy development, vast number of scientific and other frameworks) plus a lot of 'batteries included', while staying relatively performant. That's why we've been using it for years at Zazzy and previous side-projects. I took some time to convert this project weblog from static pages to a full-fledged Django project. I wanted to have a full-fledged playground to implement some ideas on semantic structuring (dynamically generated), visualisations (with D3.js), and to have the ecosystem of data-related and ML packages at hand for cool self-hosted projects.
While there are many introductory resources available for any existing technology, it is harder to find more advanced 'best practices' books. Tricks and good habits are often learned by trial and error instead. Two Scoops of Django is such a book, containing many useful tips on how to organise, grow, and maintain existing Django projects. The book was useful as a blueprint for setting up the project weblog with clean architecture, reusable components, newly discovered Django components, asynchronous tasks (Celery), and good practices concerning tests, logging, and DevOps. It also reminded me of some of the limitations of Django, such as lack of integration with modern frontend frameworks and (reactive) web-sockets.
Docker
Containerisation is taking over the world of DevOps. Where it was previously unavoidable to standardise the development stack to some extend for both developers and production servers, these days containers make it possible to run whatever stack you want in whatever environment. Conceptually, it extends developers' control level from language package managers (pip, npm, gem) to the full operating system. Although containers have existed for a while, there weren't many developer-friendly tools to make using them frictionless. Docker seems to be the answer, taking many existing encapsulation technologies inside Linux and wrapping it into an easy to use set of tools.
Over a number of weekends, I dove into the excellent Docker documentation, Dockerised old projects, and started creating useful base containers for computer vision projects. When at it, I also Dockerised my project weblog, simplifying development and deployments, and making it easier to add micro-services (the next hype!) later on.
The Things Network (part 2)
As The Things Network continued in its quest to take over the IoT world, I helped out preparing their popular Kickstarter campaign by creating a landing page to Estimate Your Gateway Impact - estimating the number of people a gateway could reach based on population data from ESA. Meanwhile, I rolled out new versions of the community platform, while helping their newly hired backend developer ramp-up until he took over to work on the community platform full-time (I had a startup to run).
Making Things Talk - Tom Igoe
My favourite book of the year was Making Things Talk. In some ways a modern rewrite of Physical Computing, this practical book gets you building things that talk to each other or the internet, without spending too much time doing low-level programming. Using Arduinos and the rich Arduino libraries ecosystem, it became much easier to focus on what you want to build instead of how, and this book fully embraces that high-level thinking. Things start becoming interesting when they start to communicate with each other, whispering to other things in the house, or on the internet.
Even after years of enthusiast tinkering with Arduinos, I found some valuable thinking patterns while playing with the examples in this book. Creating simple protocols allows for extensibility, also in the physical space (e.g., multiplayer games with physical controllers), and existing projects stay future-proof as more protocols become feasible for the still constrained microcontrollers (bluetooth, wifi, 3G, LoRaWAN). Also, standardising on a personal set of cookie-cutter prototypes (such as Arduino sketches, or laser-cutted controllers) speeds up the development. Take existing objects and connect them to the internet. Understand your environment by using the simplest sensors you can get away with. And have fun while creating some awesome talkative art!
DIY / woodworking
For our house-warming party, I created a full-size photo-booth for guests to take photos they could take home. It included an old-school screen, buttons, countdown, mini photo printer, curtains, spotlights, and epic background music. You can find the dirty script and some photos at the github repository.
Readings
Pragmatic Thinking & Learning - Andy Hunt
A pragmatic book by the writer of the influential The Pragmatic Programmer that contains a collection of tips on how to learn and think. Inspired by brain research, it gives a nerdy journey into productivity and learning techniques. Besides the cognitive insights this book gives a wealth of one-liner tips and exercises to help train your brain for life-long learning in the field of computer science and engineering.
Soft Skills - John Sonmez
This somewhat (too) self-promoting book covers a wide range of non-technical topics related to the software developer's life. Many of the short chapters have surprisingly good content that gives insights into areas which a developer early in its career might not have thought about much, including salary negotiation, effective communication, startups vs corporates, self-promotion, teaching, and productivity hacks. Other chapters are of lesser value or oversimplified.
The Second Machine Age - Brynjolfsson & Mcafee
A strong and well-structured discussion on digitisation. Talks about current developments in tech, including digitisation and zero-marginal costs, exponential developments already brought us at the 'second half of the chessboard', and combinatorial possibilities of highly complex technological building blocks. The consequences are vast: enormous productivity gains (GDP and non-economic), and increased income/productivity/skill inequality due to winner-takes-all network effects on a global scale. The authors also dedicate some chapters with heuristics on how to navigate the 21th century, both on individual - focus on ideation - and policy level - focus on education system, explore income sources other than labour, like basic income.
No Place to Hide - Glenn Greenwald
The Snowden Revelations have had a big impact on the public debate of privacy and state surveillance. This angry book tries to capture the outrage caused by the biggest leak in the history of the NSA. As one of the main characters involved in the reporting, Glenn describes the initial contact with Edward Snowden and months of reporting and threats that followed. Although the writer might not have the tightest grip on technical details, the message he brings across is fundamental to the values of freedom, lawfulness, and a functioning democracy.
Hackers
Hackers is a classic on the beginnings of the computer and internet industry. It covers early mainframes and the original MIT hackers from the 50s and 60s, early home computer entrepreneurs and Californian hippies from the 70s, the birth of the computer gaming industry and marketisation of the industry in the 80s, and early days of internet companies, tech startups, hackerspaces and Linux. A historically interesting (long!) read that will help any 21th century technology enthusiast understand the origins of the industry.
Und jetzt?
After 4 years of startup madness, I slowly started looking at alternative paths for the next few years. The startup path has been an amazing journey and we made significant progress, but the startup I founded hasn't been growing at Unicorn speed (yet?). Since I don't want to get stuck doing the same thing for a decade, I prepared for and interviewed with a couple of other companies, ending up accepting an offer from Amazon. It was time to jump on a much, much bigger ship.